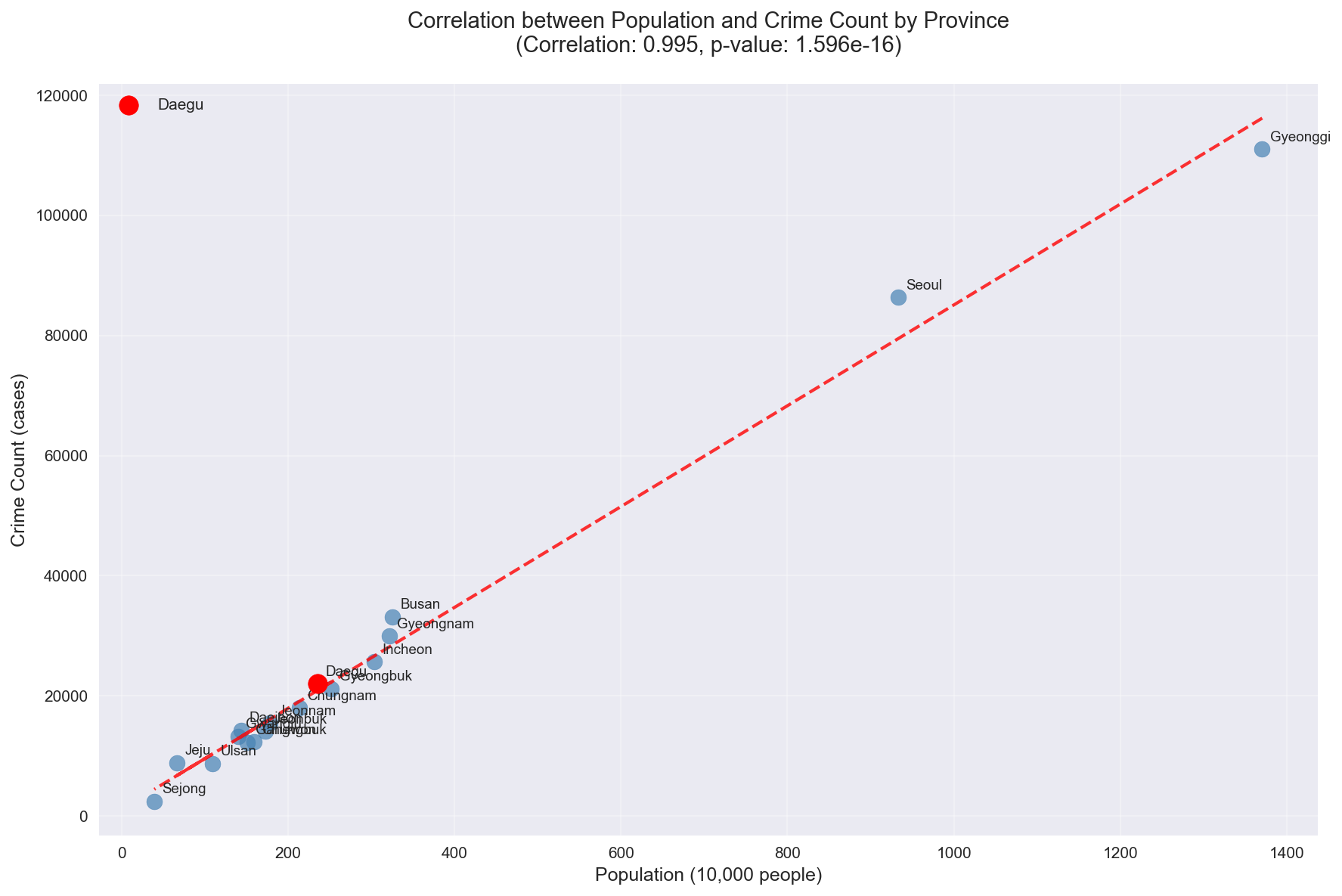
대구시는 전국 평균 범죄율에서 중간 수준에 위치하고 있으나, 울산(13.07건/1,000명), 부산(10.18건/1,000명) 등 인접 지역 대비 상당한 수준의 범죄율을 보이고 있습니다. 특히 2025년부터 검거율이 감소하는 추세를 보이고 있어, 이러한 문제를 해결하기 위한 데이터 기반의 체계적 접근이 필요한 시점입니다.
범죄발생수 추정 방법론
동별 범죄 통계가 공개되지 않는 현실적 제약을 고려하여, 다음 공식을 통해 행정동별 범죄발생수를 추정했습니다:
분석 결과: 전국 시도별 인구수와 범죄발생수는 매우 높은 양의 상관관계(r > 0.9)를 보여, 인구비례 배분이 통계적으로 타당함을 확인했습니다.
Code
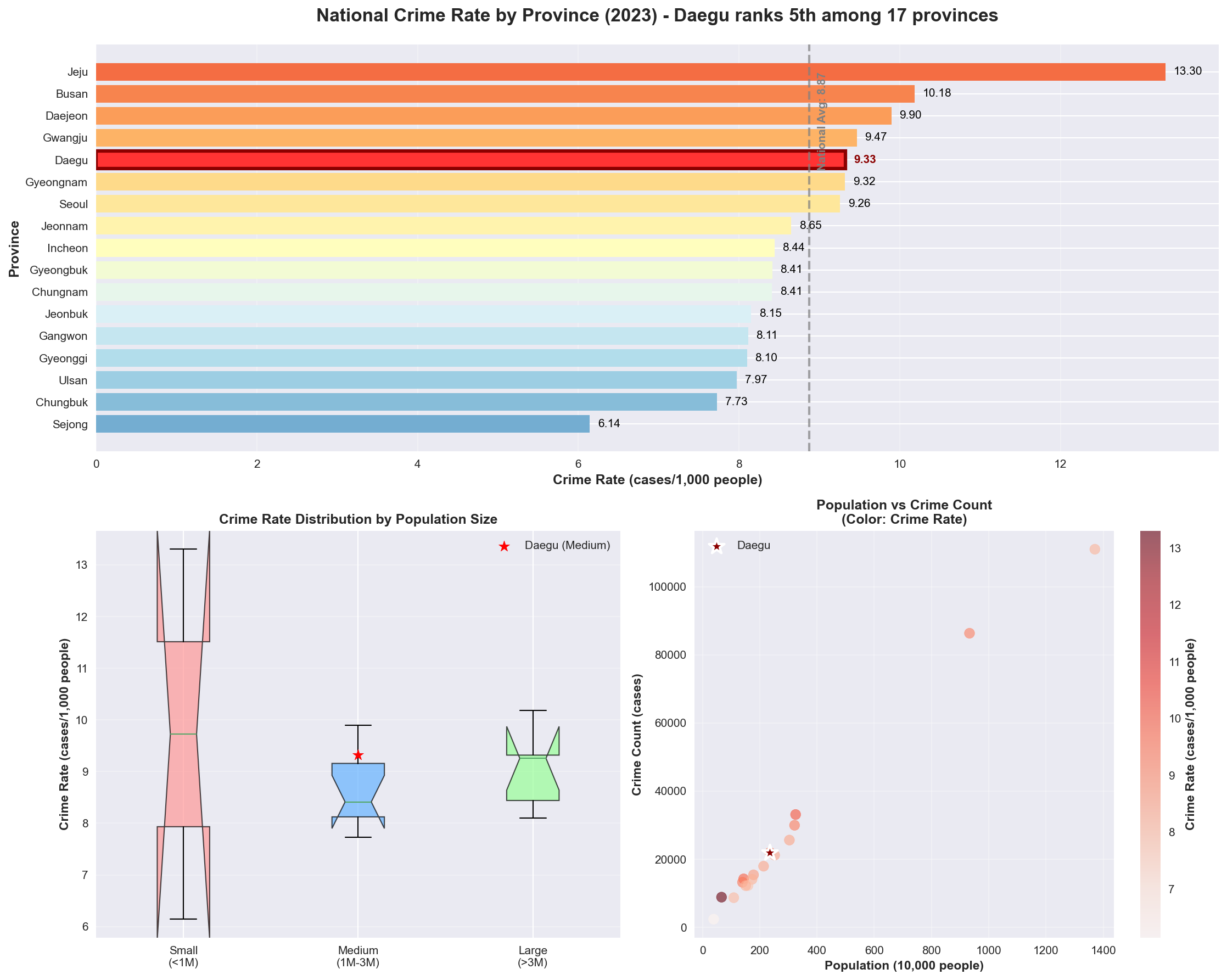
# 추가 시각화: 범죄율 순위 막대그래프df_national['Crime_Rate'] = df_national['Crime_Count'] / df_national['Population'] *1000df_sorted = df_national.sort_values('Crime_Rate', ascending=True)# 대구 위치 확인daegu_rank = df_sorted.reset_index().index[df_sorted['Region'] =='Daegu'].tolist()[0]# 색상 설정 (대구는 빨간색, 나머지는 그라데이션)colors = plt.cm.RdYlBu_r(np.linspace(0.2, 0.8, len(df_sorted)))colors[daegu_rank] = [1, 0.2, 0.2, 1] # 대구만 빨간색plt.figure(figsize=(15, 12))# 서브플롯 1: 범죄율 순위plt.subplot(2, 1, 1)bars = plt.barh(df_sorted['Region'], df_sorted['Crime_Rate'], color=colors)# 대구 막대에 테두리 추가bars[daegu_rank].set_edgecolor('darkred')bars[daegu_rank].set_linewidth(3)# 값 표시for i, (idx, row) inenumerate(df_sorted.iterrows()): plt.text(row['Crime_Rate'] +0.1, i, f'{row["Crime_Rate"]:.2f}', va='center', fontweight='bold'if row['Region'] =='Daegu'else'normal', color='darkred'if row['Region'] =='Daegu'else'black')plt.xlabel('Crime Rate (cases/1,000 people)', fontsize=12, fontweight='bold')plt.ylabel('Province', fontsize=12, fontweight='bold')plt.title('National Crime Rate by Province (2023) - Daegu ranks 5th among 17 provinces', fontsize=16, fontweight='bold', pad=20)# 전국 평균선 추가avg_rate = df_national['Crime_Rate'].mean()plt.axvline(avg_rate, color='gray', linestyle='--', alpha=0.7, linewidth=2)plt.text(avg_rate +0.1, len(df_sorted) -1, f'National Avg: {avg_rate:.2f}', rotation=90, va='top', color='gray', fontweight='bold')plt.grid(axis='x', alpha=0.3)# 서브플롯 2: 인구규모별 분석plt.subplot(2, 2, 3)df_national['Population_Size'] = pd.cut(df_national['Population'], bins=[0, 1000000, 3000000, float('inf')], labels=['Small\n(<1M)', 'Medium\n(1M-3M)', 'Large\n(>3M)'])box_data = [df_national[df_national['Population_Size'] == category]['Crime_Rate'] for category in df_national['Population_Size'].cat.categories]bp = plt.boxplot(box_data, labels=df_national['Population_Size'].cat.categories, patch_artist=True, notch=True)# 박스 색상 설정colors_box = ['#ff9999', '#66b3ff', '#99ff99']for patch, color inzip(bp['boxes'], colors_box): patch.set_facecolor(color) patch.set_alpha(0.7)# 대구 데이터 포인트 추가daegu_category = df_national[df_national['Region'] =='Daegu']['Population_Size'].iloc[0]daegu_rate = df_national[df_national['Region'] =='Daegu']['Crime_Rate'].iloc[0]category_index =list(df_national['Population_Size'].cat.categories).index(daegu_category) +1plt.scatter(category_index, daegu_rate, color='red', s=100, zorder=5, marker='*', label='Daegu (Medium)')plt.ylabel('Crime Rate (cases/1,000 people)', fontweight='bold')plt.title('Crime Rate Distribution by Population Size', fontweight='bold')plt.legend()plt.grid(axis='y', alpha=0.3)# 서브플롯 3: 인구수 vs 범죄발생수plt.subplot(2, 2, 4)scatter = plt.scatter(df_national['Population']/10000, df_national['Crime_Count'], s=80, alpha=0.6, c=df_national['Crime_Rate'], cmap='Reds')# 대구 강조daegu_data = df_national[df_national['Region'] =='Daegu']plt.scatter(daegu_data['Population']/10000, daegu_data['Crime_Count'], s=200, color='darkred', marker='*', label='Daegu', zorder=5, edgecolor='white', linewidth=2)plt.xlabel('Population (10,000 people)', fontweight='bold')plt.ylabel('Crime Count (cases)', fontweight='bold')plt.title('Population vs Crime Count\n(Color: Crime Rate)', fontweight='bold')# 컬러바 추가cbar = plt.colorbar(scatter)cbar.set_label('Crime Rate (cases/1,000 people)', fontweight='bold')plt.legend()plt.grid(alpha=0.3)plt.tight_layout()plt.show()# 상관관계 요약 정보 출력print("="*50)print("전국 시도별 범죄 현황 요약")print("="*50)print(f"최고 범죄율: {df_national.loc[df_national['Crime_Rate'].idxmax(), 'Region']} "f"({df_national['Crime_Rate'].max():.2f}건/1,000명)")print(f"최저 범죄율: {df_national.loc[df_national['Crime_Rate'].idxmin(), 'Region']} "f"({df_national['Crime_Rate'].min():.2f}건/1,000명)")# 대구 순위 제대로 계산 (높은 순서부터)df_rank_high_to_low = df_national.sort_values('Crime_Rate', ascending=False)daegu_rank_correct = df_rank_high_to_low.reset_index().index[df_rank_high_to_low['Region'] =='Daegu'].tolist()[0] +1print(f"대구 범죄율: {df_national[df_national['Region']=='Daegu']['Crime_Rate'].iloc[0]:.2f}건/1,000명 "f"(전국 {daegu_rank_correct}위)")print(f"전국 평균: {df_national['Crime_Rate'].mean():.2f}건/1,000명")print(f"인구수-범죄발생수 상관계수: {correlation:.4f} (매우 강한 양의 상관관계)")
전국 시도별 범죄율 순위 및 인구규모별 분석
==================================================
전국 시도별 범죄 현황 요약
==================================================
최고 범죄율: Jeju (13.30건/1,000명)
최저 범죄율: Sejong (6.14건/1,000명)
대구 범죄율: 9.33건/1,000명 (전국 5위)
전국 평균: 8.87건/1,000명
인구수-범죄발생수 상관계수: 0.9951 (매우 강한 양의 상관관계)
1.2 연구 목적
다양한 공공데이터를 통합 분석하여 범죄 발생이 집중되는 위험지역을 식별하고, 이를 바탕으로 안전도 향상 방안을 도출하는 것을 목표로 합니다.
1.3 분석 범위
공간적 범위: 대구광역시 전체 행정동 (135개)
시간적 범위: 2023년 기준 데이터
분석 대상: 안전 인프라, 지역 특성, 인구통계, 범죄발생 현황
데이터 수집 및 구조
2.1 데이터 소스
본 연구에서는 13개 공공데이터 소스를 활용하여 종합적인 분석을 수행했습니다.
안전 인프라 데이터 - 대구광역시 CCTV 정보 (local data) - 대구광역시 안전비상벨 위치정보 (local data) - 대구광역시 가로등 현황 (공공데이터포털) - 대구광역시 보안등 현황 (공공데이터포털)
치안 시설 데이터 - 대구광역시 관서별 경찰서 위치 (공공데이터포털) - 대구광역시 치안센터 위치 (공공데이터포털)
지역 특성 데이터 - 대구광역시 유흥주점 현황 (공공데이터포털) - 대구광역시 상가정보 (소상공인시장진흥공단) - 대구광역시 학교 위치 (공공데이터포털) - 대구광역시 대학교 위치 (공공데이터포털)
인구통계 데이터 - 대구광역시 동·읍·면별 세대 및 인구 (공공데이터포털)
범죄 통계 데이터 - 전국 범죄 발생 지역별 통계 데이터 2023년 (KOSIS)
2.2 최종 데이터셋 구조
데이터 통합 과정을 거쳐 다음과 같은 구조의 최종 데이터셋을 구성했습니다.
총 135개 행정동 × 40개 변수
인구통계 변수 (12개) - 세대수, 등록인구(남/여), 한국인(남/여), 외국인(남/여) - 세대당 인구, 65세 이상 고령자, 평균연령, 인구밀도, 면적
안전 인프라 변수 (6개) - 치안기관, 가로등 수, 보안등 수 - 어린이용 CCTV 수, 전체 CCTV 수, 안전비상벨 수
지역 특성 변수 (14개) - 유흥업소 수, 초등학교 수, 중고등학교 수, 대학교 수 - 상가 수, 요리주점, 일반 유흥주점, 입시·교과학원 - 생활방범 CCTV, 기타 CCTV, 시설물 CCTV, 쓰레기단속 CCTV
종속 변수 (3개) - 범죄발생수(유동인구기준), 강력범죄, 절도범죄, 폭력범죄
※ 범죄발생수는 구별 통계를 인구비례로 동별 배분하여 산출
데이터 전처리 과정
3.1 좌표 변환 및 행정동 매핑
주소 → 좌표 변환 카카오 지도 API를 활용하여 주소 정보를 위도/경도 좌표로 변환했습니다.
좌표 → 행정동 변환 - 1차: 카카오 API 리버스 지오코딩 - 2차: VWorld API로 세부 행정동 정보 보완 - 3차: KNN 모델을 이용한 결측 행정동 예측
1. 순위험도 분석 - 실시간 가중치 조절: 사이드바에서 위험요소와 안전요소별 가중치를 슬라이더로 조정 - 위험도 지도: 대구시 행정동별 순위험도를 색상으로 표현한 인터랙티브 지도 - 실시간 순위 테이블: 가중치 변경에 따른 행정동별 순위험도 실시간 업데이트 - 상관관계 분석: 계산된 순위험도와 실제 범죄발생수 간의 산점도 및 상관계수 표시
2. 개별 항목 시각화 - 요소별 지도 시각화: 치안기관, CCTV, 인구밀도 등 각 변수를 개별적으로 지도에 표시 - 색상 구분: 안전요소(파란색 계열), 위험요소(빨간색 계열)로 직관적 구분 - 프로그레스 바 테이블: 각 행정동별 해당 변수의 상대적 수치를 진행률 바로 표시 - 정렬 및 필터링: 수치 기준 정렬을 통한 상위/하위 지역 쉬운 파악
3. 위험지역 분석 - 상위 6개 위험지역 심층 분석: 진천동, 신당동, 안심1동, 월성1동, 관문동, 무태조야동 - 패턴 분석 차트: 전체 평균 대비 비율을 막대그래프로 시각화 - 지역별 상세 카드: 각 위험지역의 특성을 색상별 카드 형태로 구성 - 진천동(1위): 극도의 인구과밀 + 안전시설 절대부족 - 신당동(2위): 외국인 초집중지역 + CCTV 거의 없음 - 안심1동(3위): 치안기관 완전공백 + 높은 인구밀도 - 공통 DNA 도출: 인구 과밀 + 치안 인프라 부족 + 외국인 집중 패턴 확인
4. 안전지역 분석 - 상위 6개 안전지역 성공요인 분석: 평리5동, 비산6동, 평리1동, 평리2동, 원대동, 성내2동 - 대조 분석: 위험지역 vs 안전지역 vs 전체평균 3way 비교 차트 - 성공 공식 제시: 적정 인구밀도 + 충분한 치안인프라 - 모범사례 카드: 각 안전지역의 우수 특성을 배지 형태로 표시 - 평리5동: 범죄ZERO 달성 + 모든 지표 우수 - 성내2동: 중심가임에도 치안기관 최우수 - 비산6동: CCTV와 밝은 밤길의 시너지
5. 분석 개요 - 대구시 범죄율 동향: 전년 동분기 대비 발생건수 증가 추이 - 검거율 하락 추세: 범죄 증가 vs 검거율 감소의 이중 문제 시각화 - 분석 필요성: 데이터 기반 치안 정책의 시급성 강조
6. 참고자료 - 인구수-범죄발생수 상관관계: 전국 17개 시도 데이터 기반 검증 - 이중축 그래프: 인구수(막대)와 범죄발생수(선그래프) 동시 표시 - 순위 테이블: 인구수 순위와 범죄발생수 순위 비교 분석 - 상관계수 표시: 강한 양의 상관관계(r≈0.995) 수치적 증명
기술적 특징 - 반응형 디자인: PC, 태블릿, 모바일 환경 모두 지원 - 실시간 연산: 가중치 변경 즉시 모든 차트와 지도 업데이트 - 고성능 지도: Plotly 기반 인터랙티브 choropleth 지도 - 데이터 캐싱: Streamlit의 @st.cache_data 활용으로 빠른 로딩 - 한글 폰트 지원: 모든 차트에서 한글 깨짐 없이 표시
사용자 경험 - 직관적 인터페이스: 탭 구조로 명확한 정보 분류 - 시각적 피드백: 호버 효과와 툴팁으로 상세 정보 제공 - 탐색적 분석: 사용자가 직접 가중치를 조절하며 시나리오 분석 가능 - 정책 시뮬레이션: 치안 인프라 투자 우선순위 결정에 활용 가능
로컬 실행 방법
# 로컬에서 실행하려면streamlit run app2.py
# Streamlit 대시보드 구조 예시import streamlit as stimport plotly.express as pximport geopandas as gpd# 페이지 설정st.set_page_config(layout="wide", page_title="대구 범죄 분석 대시보드")# 데이터 로딩@st.cache_datadef load_data(): crime_data = pd.read_csv("daegu_crime_data.csv").fillna(0) daegu_map = gpd.read_file("daegu_map.geojson")return crime_data, daegu_map# 위험도 계산 함수def calculate_risk_score(data, risk_weights, safety_weights): total_risk =sum(data[factor] * weight for factor, weight in risk_weights.items()) total_safety =sum(data[factor] * weight for factor, weight in safety_weights.items())return total_risk - total_safety# 지도 시각화def create_risk_map(gdf, color_column): fig = px.choropleth_mapbox( gdf, geojson=gdf.geometry, locations=gdf.index, color=color_column, opacity=0.6, center={"lat": 35.8714, "lon": 128.6014}, mapbox_style="carto-positron", zoom=10 )return fig
분석 결과
7.1 주요 발견사항
데이터 규모 - 총 135개 행정동 분석 완료 - 40개 변수를 활용한 종합적 분석 - 13개 공공데이터 소스 성공적 통합
상관관계 분석 결과 - 범죄발생과 상관계수 0.15 이상인 주요 변수 식별 - 인구밀도, 상가 수, 유흥업소 등이 위험요소로 확인 - CCTV, 경찰시설 등이 안전요소로 작용
PCA 분석 결과 - 첫 2개 주성분으로 지역 특성의 주요 패턴 설명 - 행정동별 안전도 클러스터링 패턴 확인
7.2 위험도 모델 적용 준비
위험도 산출을 위한 모든 준비 작업이 완료되었으며, 다음 단계에서 실제 위험도 계산 및 검증을 수행할 예정입니다.
모델 구성요소 - 위험요소 11개 변수와 가중치 설정 완료 - 안전요소 6개 변수와 가중치 설정 완료 - 실제 범죄발생률과의 검증 방법론 수립
결론
본 연구는 대구광역시의 다양한 공공데이터를 체계적으로 통합하여 범죄 취약지역 식별을 위한 데이터 기반을 구축했습니다. 13개 데이터 소스를 성공적으로 통합하고, 135개 행정동에 대한 종합적인 분석 기반을 마련했습니다.
상관관계 분석과 PCA를 통해 범죄발생에 영향을 미치는 주요 요인들을 식별했으며, 문헌 조사를 바탕으로 한 위험도 산출 모델을 설계했습니다. 이러한 데이터 기반 접근법은 효과적인 치안 정책 수립과 예산 배분의 효율성 제고에 기여할 것으로 기대됩니다.